

Before disassembling, keep in mind that there may be several types of information in a Z80 assembler program.
Program mnemonics, consisting of a series of processor-specific byte codes, jump, address, and data information related to the called functions.
A byte (or more) needle to a specific function, a bit like an elevator and its floors.
Code 00 gives the order of the NOP: No Operand.
The 01 gives an LD (Load) command, and BC load with the following value ... LD BC = +2 bytes.
the incrementation of the steps (the PC) of the processor is automatic and depends on the function.
For a NOP, it is a 1 byte offset, to read the next function.
For a LD BC, xx is 3 steps, because BC is a register called "Pair" in 2 bytes, the command 1 byte.
A small peculiarity for reading the data is that these data are archived in the reverse order of natural reading, so if BC = 00AA in hexadecimal, it is noted 01 (LD function): AA (C): 00 (B)
01, AA, 00 will be disassembled: LD BC, $ 00AA
list of mnemonics.
In an ideal world, an assembler program will consist only of registry functions and data.
But sometimes you have to store text, temporary data and persistent information.
To disassemble it, everything is code, and even the text will be treated as instructions to execute.
It is thus necessary to differentiate data, text and mnemonic of execution.
For this, we have the visual method and the method of identifying numerical values.
Take an example on VB81, with an assembler program.

It is necessary above all to marger the assembler program, generally included in a REM, with a low address and a high address ... including all the code with the datas.
A click can select a particular REM line, but sometimes the "user" mode is required to include multiple lines.
Margins can be manually set at the top of the disassembly window.
Only the dither portion will be disassembled when exporting source codes.
If the notation in Hexadecimal is problematic, click on the header of the address column to change this notation .... same thing for the address values (Hexa, decimal and text).

With the binary display window, check the address of the text data and switch to text mode in the disassembly window (left click on the column header).
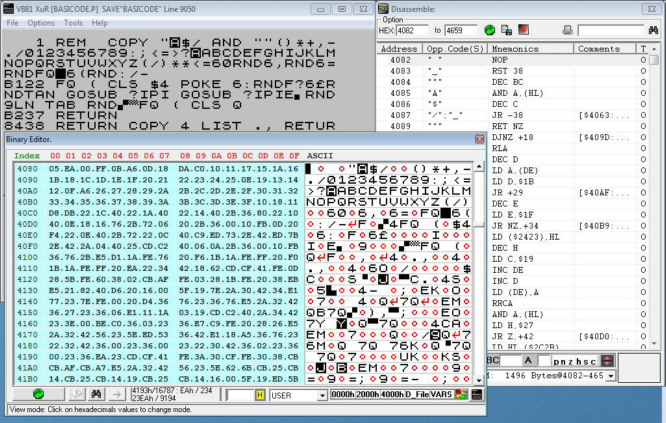
In order to differentiate the non-active data (DATA and TEXT), it suffices, with a right click, to give the nature of a zone ... or an address ... then with the support of "Shift" after the right click ... the cursor changes and a second right click fills the area between the first and the second address, with the data info of the first address.

So we have a DATA option which reserves the place for the byte, text in ZX81 mode, text in ASCII and processing in OP. Machine language code (default).
The choice of this information is purely cosmetic and will allow the embedded disassembler of the VB81, to modify the notation of the information and not to disassemble certain codes in DATA (part in Basic between the lines REMs).
In .db "A", "B", "C", "D", "E", "F" for the text.
In .db $ 01, $ 02, $ 03, $ 04, $ 05 for the datas and the rest will be in Op. Codes.
Note: To select several values, in a Text or Data bloc, select the first address using the right click, press shift key (nothing else). The mouse pointer will change, and select the last address using the right click.
For export, it's simple (!?!).

In "Datas type", it is possible to save the disassembly information in a file ".arr", in order to find them later with the "LOAD".
The blue squares with the arrow allow a "Copy" in the clipboard ... in text mode (faster, no backup!).
The standard button allows you to save the file in text mode.

The result will give you a source code with call labels, jumps, datas and ZX characters directly exploitable in TASM.
Disassembly works for Spectrum, CPC, MSX CODES ... but some information specific to ZX81s may be misinterpreted ... like IO, basic variable addresses between 4000-4080. etc ...
The 64K are usable, but in this case, it will be necessary to block the emulator, to avoid the crash (emulation of the implanted code).
For the binary layout, it is the gray square with a red arrow ... but be careful, to avoid overwriting the REMs lines on ZX81, the emulator does a filling of the binary on the bounded part that you have defined at advance. So, if the publisher is $ 4000 to $ 4100 ... the implanted code will be $ 100 bytes ... and not one more!
It is therefore necessary to put in "USER" to define a higher high limit in case of overflow, not forgetting to "refresh" the defined zone.
Note:
Only the REM or USER's room will be disassembled. Check the address rang to select all the ASM sub-routines. (to expend the dissembler click on the text range box HEX/DEC [] to [], and rang the top or the bottom rang)…. the "Address" column header click, will change the Hexadecimal or Decimal display, in the address rang selector.
In case of 'multi-REM' program, just set the line basic data infos to DATAs arguments.
It will set the future values in pure DATAs …
Output DATAs values, in 'db' output format, seem buggy… just add a ".db" directive in the text file, if the line is corrupt. (fist line).
The output file check the DATA locations, direct Jumps and relative jumps !
In case of corrupt disassembled datas, this opcodes will generate several jump/datas errors.
Especially in an "auto-morph" program, how directly change the opcodes values…
LD A,$00 … the Label will be in an opcode… and we had to move the label (LBxxx+1) to avoid to cut the 'LD a," command. (in DATA infos .db $3E,$xx! )
The "Uncharted" comment tag is an orphelin address (Not taged as DATAs ou TEXT), and not used in the global ASM Routine (CALL,JR or JP not found on this label)… It can be a RAND USR start, or an empty memory segment.
All RAND USR in Basic, will be charted in the disassembled text. (if the Basic program is present in memory)
Have fun.
Xav.